
Context
This is Part II of investigating how R1 does verifications. For additional context, see Part I.
How does R1 know it’s found a solution?
R1 will often claim that it’s found a solution. How does it represent the solution, or even the fact that it has found a solution?
Currently I am working with a hypothesis that R1 has some internal representation for “I’ve found and verified a solution”, and that this representation generates “solution tokens” (such as “Therefore the answer is…”).
Here I present some of my thoughts on the latter part – how “solution tokens” are generated.
(Recap from Part I) Model:
As a reminder, we are working with a model trained on a specific reasoning task (a countdown task). Given 3 or 4 “operand” numbers (ex: 67, 90, 60, 12) and a target number (ex: 49), R1 needs to find an arithmetic combination that produces the target number. See Part I for details.
Luckily, this means we know the exact token to look for when the model has found a solution. Namely, the model always outputs in a structured format:
- 90 - 67 - 60 + 12 = -15 (not 49)
- 90 - 67 + 60 - 12 = 71 (not 49)
- 90 - 67 + 12 - 60 = -15 (not 49)
- 90 - 60 - 12 + 67 = 85 (not 49)
- 67 + 60 - 90 - 12 = 25 (not 49)
- 67 + 90 - 60 - 12 = 85 (not 49)
- 67 + 90 + 12 - 60 = 109 (not 49)
- 67 + 60 + 12 - 90 = 49 (this works)
So, the equation that equals 49 is 67 + 60 + 12 - 90. </think>
<answer> (67 + 60 + 12) - 90 </answer><|endoftext|>
Thus, we have a specific timestep (right when a “(“ is predicted, and when “this” will be predicted next) where we can do a deep dive.
Good old Logitlens
So let’s start by seeing what’s encoded at each layer, right before “this works” is generated. Here’s an example:
(I recommend that you view it via this interactive html link)
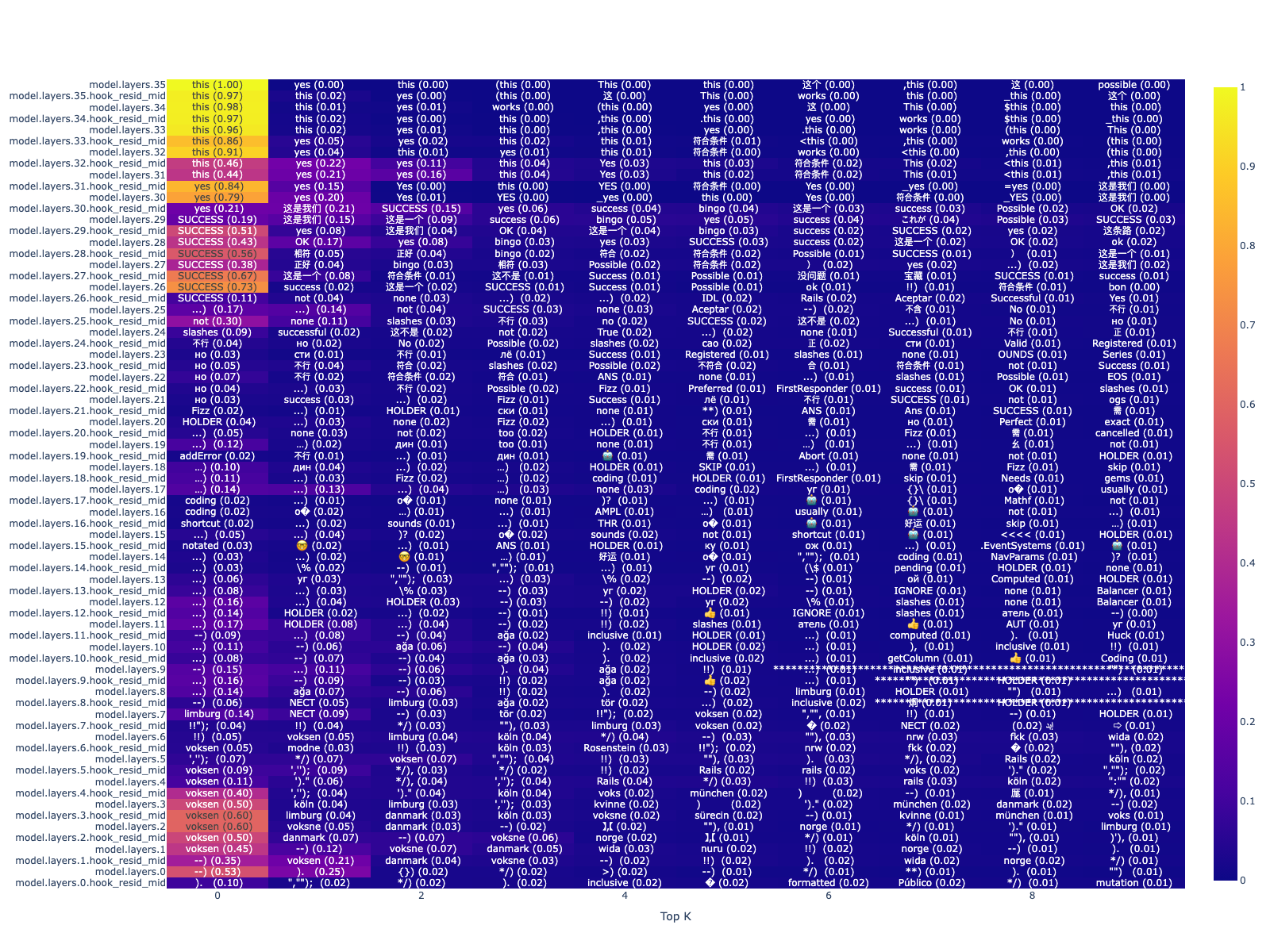
So we see some interesting tokens show up in mid layers, like “success”, “OK”, “bingo”, “yes”. In the later layers, the model decides on predicting “this”.
Interestingly, even in the previous timestep (when it’s predicting the “(“ token), you can see words like “success” still show up:
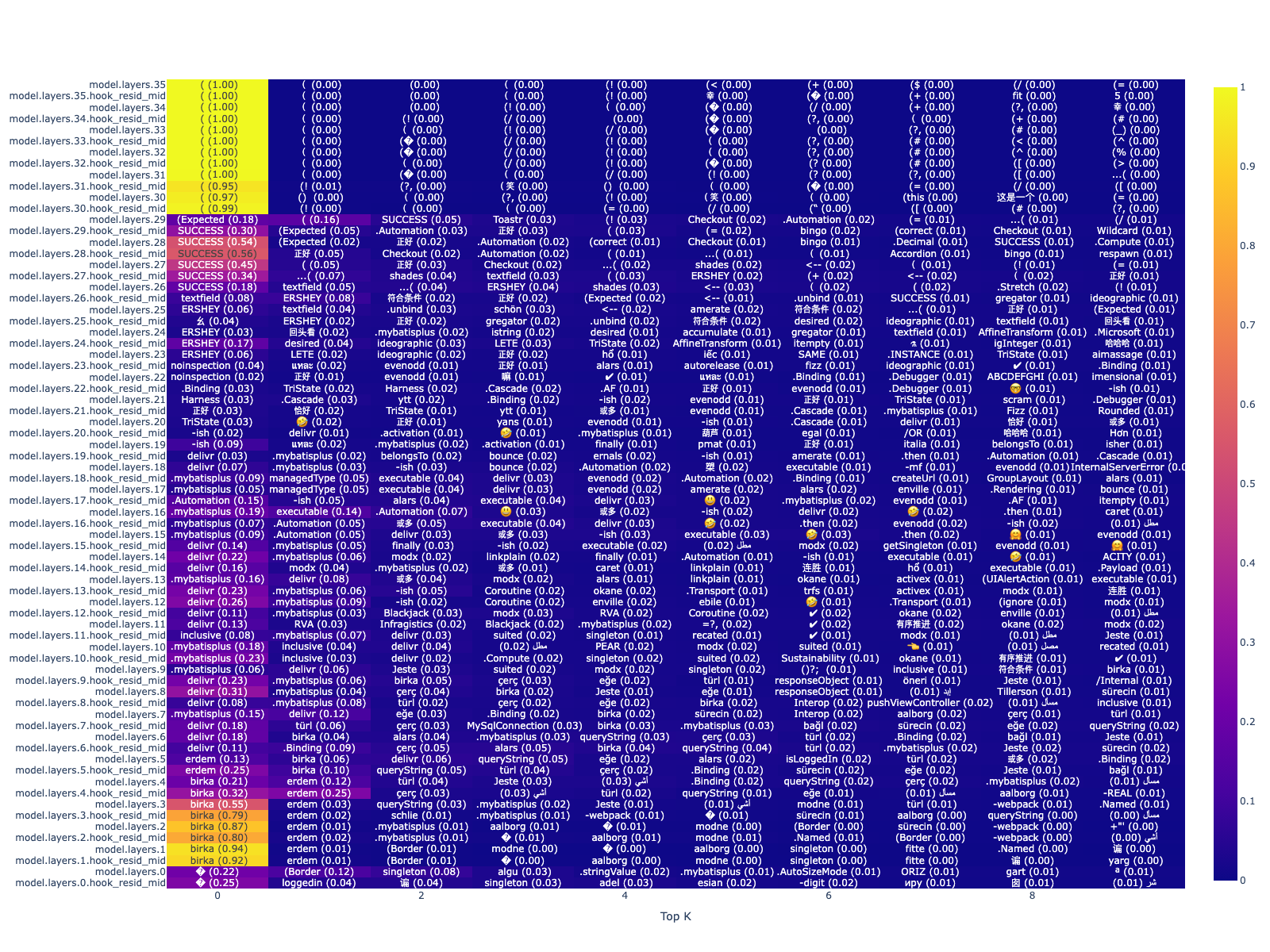
In this post I will discuss the role that MLP blocks play in generating the tokens seen in mid layers, as well as potentially the final predictions.
Looking at MLP “Value Vectors”
I like to think of MLP blocks by rows and columns: Instead of $ MLP(x) = \sigma(W_kx)W_v $, we can express MLPs as $ MLP(x) = \sum_i^{d_{mlp}} = \sigma(x \cdot k_i)v_i $, where $k_i, v_i \in R^d$ are the $i$-th row and column of $W_k$ and $W_v$ respectively.
I will refer to $k_i$ as key vectors, and $v_i$ as value vectors.
Put differently, we can think of the output of an MLP as a weighted sum of the value vectors, where the weights are given by the dot product of the input and key vectors.
So it turns out that you can also project your value vectors onto the token embedding space, and sometimes you’ll see coherent semantic clusters show up.
But which value vectors should we look at? In the case of Qwen2.5-3B, we have 36 layers, each with 11008 value vectors. We can’t examine all of them.
Instead, we can rely on our probe (see Part I) to guide us.
Namely, we can think of probe W[0] as encoding “This is not correct” and W[1] as “This is correct”.
Luckily, these probes are also in $R^d$.
So we can simply take the cosine similarity scores between each of our value vectors and our probes, and look at the ones with highest similarity.
(I think of value vectors that rank highest here as vectors that contribute the most towards one of the W directions. This is mainly because transformers use residual connections.)
Here are some examples:
For W[0] (“Not found answer yet”):
(I am using MLP[layer, index] to denote the value vector at layer layer and index index.)
| Layer, Index | Nearest Neighbors (k = 10) |
|---|---|
| MLP[32, 5650] | ’ não’, ‘ nicht’, ‘不’, ‘不在’, ‘ không’, ‘不会’, ‘ не’, ‘ 不’, ‘不會’, ‘不是一个’ ‘não’, ‘nicht’, ‘not’, ‘not’, ‘không’, ‘won’, ‘не’, ‘no’, ‘won’, ‘not a’ |
| MLP[32, 767] | ’ không’, ‘没有’, ‘ nicht’, ‘ not’, ‘不会’, ‘不能’, ‘ neither’, ‘ não’, ‘ไม’, ‘沒有’ ’ không ‘, ‘no’, ‘ nicht ‘, ‘ not ‘, ‘won’, ‘can’t’, ‘ neither ‘, ‘ não ‘, ‘ไม ‘, ‘no’ |
| MLP[30, 6404] | ‘不是’, ‘并非’, ‘ not’, ‘不是一个’, ‘也不是’, ‘not’, ‘ NOT’, ‘\tnot’, ‘并不是’, ‘不再是’ ‘is not’, ‘is not’, ‘not’, ‘is not a’, ‘is not’, ‘not’, ‘NOT’, ‘\tnot’, ‘is not’, ‘is not’ |
| MLP[26, 744] | ‘未能’, ‘不够’, ‘ nicht’, ‘不像’, ‘达不到’, ‘不清楚’, ‘不具备’, ‘不到位’, ‘不符’, ‘还不’ ‘failed’, ‘not enough’, ‘ nicht’, ‘not like’, ‘cannot reach’, ‘not clear’, ‘not available’, ‘not in place’, ‘not in line’, ‘not yet’ |
| MLP[31, 10127] | ’ not’, ‘ không’, ‘ nicht’, ‘不会’, ‘不能’, ‘不是’, ‘ не’, ‘not’, ‘\tnot’, ‘ não’ ’ not’, ‘ không’, ‘ nicht’, ‘won’, ‘can’t’, ‘is not’, ‘ не’, ‘not’, ‘\tnot’, ‘ não’ |
| MLP[23, 7356] | ‘不利于’, ‘造成了’, ‘会造成’, ‘严重影响’, ‘禁止’, ‘ threaten’, ‘ threatens’, ‘不可避免’, ‘严重’, ‘ caution’ ‘unfavorable’, ‘caused’, ‘will cause’, ‘seriously affect’, ‘prohibit’, ‘threaten’, ‘threatens’, ‘inevitable’, ‘serious’, ‘caution’ |
| MLP[26, 6619] | ‘缺乏’, ‘缺少’, ‘不方便’, ‘ lacks’, ‘难以’, ‘未能’, ‘无法’, ‘ lack’, ‘得不到’, ‘不符合’ ‘lack’, ‘lack’, ‘inconvenience’, ‘lacks’, ‘difficult’, ‘failed’, ‘cannot’, ‘lack’, ‘cannot get’, ‘not in line with’ |
| MLP[30, 10722] | ‘不会’, ‘不會’, ‘也不会’, ‘都不会’, ‘ doesn’, ‘并不会’, ‘ neither’, ‘ doesnt’, ‘ nicht’, ‘ never’ ‘won’t’, ‘won’t’, ‘nor’, ‘neither’, ‘ doesn’, ‘ not’, ‘ neither’, ‘ doesnt’, ‘ nicht’, ‘ never’ |
| MLP[27, 9766] | ‘是不可能’, ‘ neither’, ‘看不到’, ‘不存在’, ‘是不会’, ‘ nowhere’, ‘ nothing’, ‘ none’, ‘没有任何’, ‘都没有’ ‘It’s impossible’, ‘neither’, ‘can’t see’, ‘doesn’t exist’, ‘will never’, ‘ nowhere’, ‘ nothing’, ‘ none’, ‘nothing’, ‘nothing’ |
| MLP[27, 4971] | ’ inefficient’, ‘没能’, ‘inity’, ‘不方便’, ‘Danger’, ‘ disadvantage’, ‘不利于’, ‘还不如’, ‘ challenged’, ‘ขาด’ ’ inefficient ‘, ‘failed ‘, ‘inity ‘, ‘inconvenient ‘, ‘Danger ‘, ‘ disadvantage ‘, ‘unfavorable ‘, ‘not as good as ‘, ‘ challenged ‘, ‘ขาด ‘ |
For W[1] (“Found answer”):
| Layer, Index | Nearest Neighbors (k = 10) |
|---|---|
| MLP[26, 6475] | ‘倒是’, ‘不失’, ‘适度’, ‘successful’, ‘.success’, ‘却是’, ‘ successful’, ‘没事’, ‘完好’, ‘还不错’ ‘It is’, ‘not lost’, ‘moderate’, ‘successful’, ‘.success’, ‘but it is’, ‘ successful’, ‘nothing’, ‘intact’, ‘not bad’ |
| MLP[29, 6676] | ’ yes’, ‘ Yes’, ‘Bindable’, ‘ exactly’, ‘Yes’, ‘“Yes’, ‘yes’, ‘ Yep’, ‘ Exactly’, ‘ included’ |
| MLP[25, 1124] | ‘ELY’, ‘怫’, ‘yes’, ‘ Awesome’, ‘itchen’, ‘没错’, ‘etur’, ‘即时发生’, ‘ños’, ‘emade’ ‘ELY’, ‘怫’, ‘yes’, ‘ Awesome’, ‘itchen’, ‘That’s right’, ‘etur’, ‘Immediate’, ‘ños’, ‘emade’] |
| MLP[27, 10388] | ’ mirac’, ‘乐观’, ‘安然’, ‘ Relief’, ‘幸’, ‘.isSuccess’, ‘.SUCCESS’, ‘ favorable’, ‘优点’, ‘顺利’ ’ mirac ‘, ‘ Optimistic ‘, ‘ Safe ‘, ‘ Relief ‘, ‘ Luck ‘, ‘.isSuccess ‘, ‘.SUCCESS ‘, ‘ favorable ‘, ‘ Advantages ‘, ‘ Smooth ‘ |
| MLP[30, 8233] | ’ correctly’, ‘正确’, ‘恰当’, ‘ accurately’, ‘符合’, ‘合适’, ‘ properly’, ‘ adequately’, ‘准确’, ‘ accurate’ ’ correctly’, ‘Correct’,’appropriate’, ‘ accurately’, ‘fit’, ‘appropriate’, ‘ properly’, ‘ adequately’, ‘accurate’, ‘ accurate’ |
Great, so we can localize where the tokens from logitlens are coming from.
This gives us a hint that these value vectors, when activated, promote the likelihood of tokens like “success” or “incorrect” to show up.
Let’s refer to value vectors similar to W[0] as “negative value vectors” and value vectors similar to W[1] as “positive value vectors”.
To confirm that these value vectors are responsible for the tokens showing up in mid-layers, we can do an intervention. Namely, what happens if we “turn off” these value vectors?
Interventions on Value Vectors
During the forward pass, we can zero out the value vectors that we think might be important.
Specifically, we can look at value vectors in the second half of the model (layers 18~36).
In each of those layers, let’s take $k$ value vectors with the highest cosine similarity to W[1], and zero them out.
Below is what happens when $k = 50$ (and therefore we’re zeroing out 50 * 18 = 900 out of 396288 (11008 * 36) value vectors. That’s about 0.2% of the total value vectors.):
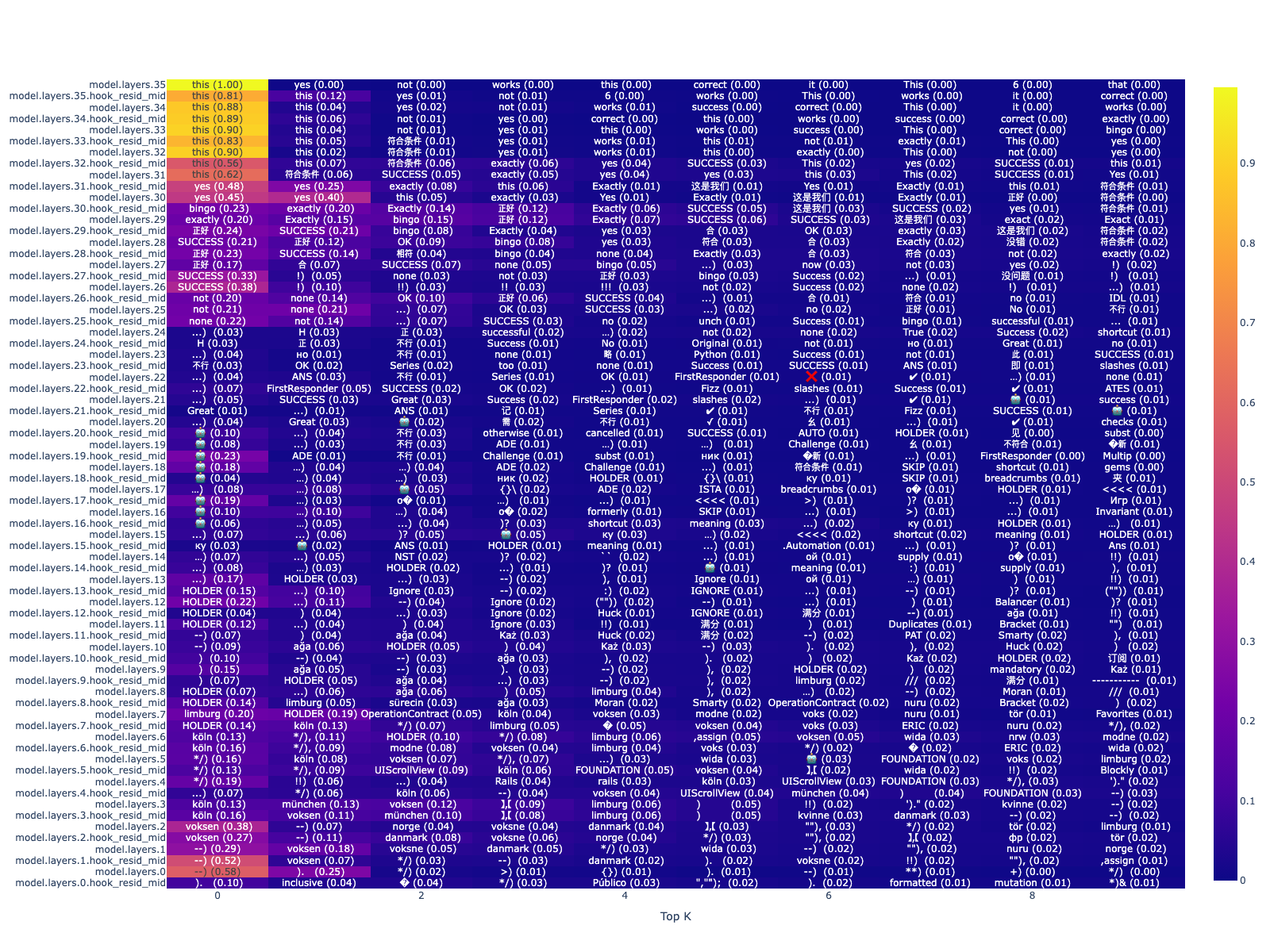
From this, we can see that while the model still predicts “this”, the likelihood of “success” and similar tokens showing up in the mid layers is reduced (It may be a bit hard to compare, but for instance, layer 26 –> P(“SUCCESS”) drops from 0.73 to 0.38).
Though we can do this for larger values of $k$, it didn’t make much of a difference.
Interestingly, we can further zero out value vectors that are also similar to W[0] (encoding “Not Solved”), in addition to W[1] (encoding “Solved”)).
So now we’re looking at zeroing out a total of 100 value vectors per layer.
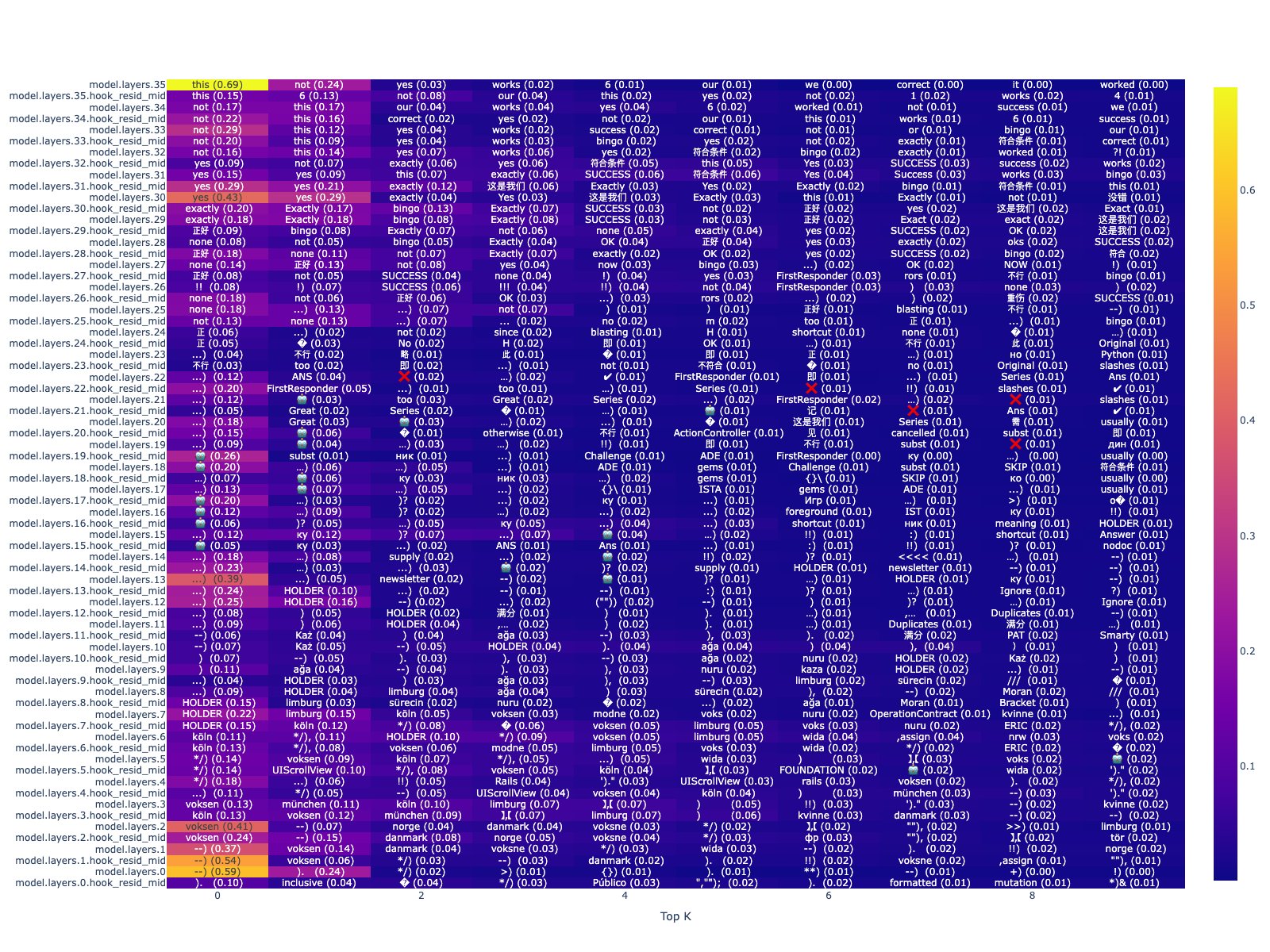
With this, we see a more pronounced effect. Many of the words similar to “success” are now no longer showing up as much in the mid layers. Furthermore, the probability of “this” only shows significantly in the last layer. In fact, the layer right before it (“model.layers.35.hook_resid_mid”), which is right after the attention heads but before the MLPs in the last layer, the probability of “this” vs. “not” is 0.15 vs. 0.08 - a much closer gap compared to when “this” had a 0.97 probability.
Wait, why do zeroing out value vectors similar to W[0] help?
Why would zeroing out negative value vectors (words encoding “Not found answer yet”) affect whether words like “success” show up in the mid layers? To answer this, we need to consider two things:
(1) Activations in hidden states tend to be sparse. This means that most value vectors tend to be inactive during a forward pass.
(2) Depending on the activation function being used (i.e., Silu), inactive value vectors can still have a non-zero effect on the output. In fact, consider the Silu curve below:
 (Source: Pytorch)
(Source: Pytorch)
Often, inactive value vectors don’t have an activation value of 0 – they have a very small, negative value! This means that during the forward pass, if a value vector is inactive, it can end up getting multiplied by a negative value – and thus, flip directions, and get added to the next layer.
With that being said, let’s revisit some of the negative value vectors. But before projecting them onto the vocabulary space, we can first multiply them by -1.
Below, I’ve marked the original value vectors in black font (e.g., MLP[27, 4971]), while the same value vector multiplied by -1 (e.g., MLP[27, 4971] * -1) are in red.
| Layer, Index | Nearest Neighbors (k = 10) |
|---|---|
| MLP[27, 4971] | ’ inefficient’, ‘没能’, ‘inity’, ‘不方便’, ‘Danger’, ‘ disadvantage’, ‘不利于’, ‘还不如’, ‘ challenged’, ‘ขาด’ ’ inefficient ‘, ‘failed ‘, ‘inity ‘, ‘inconvenient ‘, ‘Danger ‘, ‘ disadvantage ‘, ‘unfavorable ‘, ‘not as good as ‘, ‘ challenged ‘, ‘ขาด ‘ |
| MLP[27, 4971] * -1 | ’ successfully’, ‘ successful’, ‘顺利’, ‘成功’, ‘删除成功’, ‘良好’, ‘ succesfully’, ‘.success’, ‘successfully’, ‘successful’ ‘ successfully’, ‘ successful’, ‘smooth’, ‘successful’, ‘successful deletion’, ‘good’, ‘ succesfully’, ‘.success’, ‘successfully’, ‘successful’ |
| MLP[26, 744] | ‘未能’, ‘不够’, ‘ nicht’, ‘不像’, ‘达不到’, ‘不清楚’, ‘不具备’, ‘不到位’, ‘不符’, ‘还不’ ‘failed’, ‘not enough’, ‘ nicht’, ‘not like’, ‘cannot reach’, ‘not clear’, ‘not available’, ‘not in place’, ‘not in line’, ‘not yet’ |
| MLP[26, 744] * -1 | ‘慎’, ‘足’, ‘同等’, ‘ tend’, ‘ONDON’, ‘足以’, ‘均衡’, ‘谨慎’, ‘ equal’, ‘fast’ ‘careful’, ‘sufficient’, ‘equal’, ‘tend’, ‘ONDON’, ‘enough’, ‘balanced’, ‘cautious’, ‘equal’, ‘fast’ |
| MLP[23, 7356] | ‘不利于’, ‘造成了’, ‘会造成’, ‘严重影响’, ‘禁止’, ‘ threaten’, ‘ threatens’, ‘不可避免’, ‘严重’, ‘ caution’ ‘unfavorable’, ‘caused’, ‘will cause’, ‘seriously affect’, ‘prohibit’, ‘threaten’, ‘threatens’, ‘inevitable’, ‘serious’, ‘caution’ |
| MLP[23, 7356] * -1 | ‘从容’, ‘ nhờ’, ‘rar’, ‘ grâce’, ‘ waive’, ‘就好了’, ‘无忧’, ‘ easier’, ‘有信心’, ‘kek’ ‘calm’, ‘nhờ’, ‘rar’, ‘grâce’, ‘waive’, ‘just fine’, ‘worry-free’, ‘easier’, ‘confident’, ‘kek’ |
| MLP[26, 6619] | ‘缺乏’, ‘缺少’, ‘不方便’, ‘ lacks’, ‘难以’, ‘未能’, ‘无法’, ‘ lack’, ‘得不到’, ‘不符合’ ‘lack’, ‘lack’, ‘inconvenience’, ‘lacks’, ‘difficult’, ‘failed’, ‘cannot’, ‘lack’, ‘cannot get’, ‘not in line with’ |
| MLP[26, 6619] * -1 | ‘不仅能’, ‘不错的’, ‘不错’, ‘具有良好’, ‘总算’, ‘这样才能’, ‘有足够的’, ‘良好’, ‘不仅可以’, ‘ sane’ ‘not only can’, ‘good’, ‘good’, ‘have good’, ‘finally’, ‘only in this way’, ‘have enough’, ‘good’, ‘not only can’, ‘sane’ |
| MLP[27, 9766] | ‘是不可能’, ‘ neither’, ‘看不到’, ‘不存在’, ‘是不会’, ‘ nowhere’, ‘ nothing’, ‘ none’, ‘没有任何’, ‘都没有’ ‘It’s impossible’, ‘neither’, ‘can’t see’, ‘doesn’t exist’, ‘will never’, ‘ nowhere’, ‘ nothing’, ‘ none’, ‘nothing’, ‘nothing’ |
| MLP[27, 9766] * -1 | ‘might’, ‘ maybe’, ‘may’, ‘maybe’, ‘ might’, ‘Maybe’, ‘有时候’, ‘部分地区’, ‘ may’, ‘.some’ ‘might’, ‘ maybe’, ‘may’, ‘maybe’, ‘ might’, ‘Maybe’, ‘Sometimes’, ‘Some areas’, ‘ may’, ‘.some’ |
It turns out the antipodes of some of the negative value vectors are encoding words you would expect from positive value vectors! So not only are we seeing positive value vectors being activated to promote tokens like (“success”), but inactive negative value vectors also get flipped to promote similar tokens.
Same thing with flipping positive value vectors:
| Layer, Index | Nearest Neighbors (k = 10) |
|---|---|
| MLP[30, 8233] | ’ correctly’, ‘正确’, ‘恰当’, ‘ accurately’, ‘符合’, ‘合适’, ‘ properly’, ‘ adequately’, ‘准确’, ‘ accurate’ ’ correctly’, ‘Correct’,’appropriate’, ‘ accurately’, ‘fit’, ‘appropriate’, ‘ properly’, ‘ adequately’, ‘accurate’, ‘ accurate’ |
| MLP[30, 8233] * -1 | ’ wrong’, ‘不良’, ‘ incorrect’, ‘wrong’, ‘ invalid’, ‘ bad’, ‘ inappropriate’, ‘invalid’, ‘不合格’, ‘不当’ ‘wrong’, ‘bad’, ‘incorrect’, ‘wrong’, ‘invalid’, ‘bad’, ‘inappropriate’, ‘invalid’, ‘unqualified’, ‘inappropriate’ |
| MLP[26, 6475] | ‘倒是’, ‘不失’, ‘适度’, ‘successful’, ‘.success’, ‘却是’, ‘ successful’, ‘没事’, ‘完好’, ‘还不错’ ‘It is’, ‘not lost’, ‘moderate’, ‘successful’, ‘.success’, ‘but it is’, ‘ successful’, ‘nothing’, ‘intact’, ‘not bad’ |
| MLP[26, 6475] * -1 | ’ also’, ‘ likewise’, ‘Also’, ‘也同样’, ‘ тоже’, ‘ também’, ‘也非常’, ‘ également’, ‘ ALSO’, ‘ Also’ ’ also’, ‘ likewise’, ‘ Also’, ‘ also’, ‘ тоже’, ‘ também’, ‘ also very’, ‘ également’, ‘ ALSO’, ‘ Also’ |
| MLP[29, 6676] | ’ yes’, ‘ Yes’, ‘Bindable’, ‘ exactly’, ‘Yes’, ‘“Yes’, ‘yes’, ‘ Yep’, ‘ Exactly’, ‘ included’ |
| MLP[29, 6676] * -1 | ‘都不’, ‘不太’, ‘ neither’, ‘不予’, ‘没见过’, ‘都不是’, ‘不曾’, ‘不开’, ‘不具备’, ‘都没有’ ‘neither’, ‘not quite’, ‘neither’, ‘not given’, ‘never seen’, ‘neither’, ‘never’, ‘not open’, ‘not possess’, ‘none’ |
| MLP[25, 1124] | ‘ELY’, ‘怫’, ‘yes’, ‘ Awesome’, ‘itchen’, ‘没错’, ‘etur’, ‘即时发生’, ‘ños’, ‘emade’ ‘ELY’, ‘怫’, ‘yes’, ‘ Awesome’, ‘itchen’, ‘That’s right’, ‘etur’, ‘Immediate’, ‘ños’, ‘emade’] |
| MLP[25, 1124] * -1 | ‘根本’, ‘Prom’, ‘ Prom’, ‘)NULL’, ‘”>×<’, ‘都不’, ‘丝毫’, ‘ari’, ‘ never’, ‘抑制’ ‘at all’, ‘Prom’, ‘ Prom’, ‘)NULL’, ‘”>×<’, ‘neither’, ‘slightly’, ‘ari’, ‘never’, ‘restrain’ |
| MLP[27, 10388] | ’ mirac’, ‘乐观’, ‘安然’, ‘ Relief’, ‘幸’, ‘.isSuccess’, ‘.SUCCESS’, ‘ favorable’, ‘优点’, ‘顺利’ ’ mirac ‘, ‘ Optimistic ‘, ‘ Safe ‘, ‘ Relief ‘, ‘ Luck ‘, ‘.isSuccess ‘, ‘.SUCCESS ‘, ‘ favorable ‘, ‘ Advantages ‘, ‘ Smooth ‘ |
| MLP[27, 10388] * -1 | ‘失败’, ‘ failure’, ‘不良’, ‘不利’, ‘糟糕’, ‘失误’, ‘ failures’, ‘ bad’, ‘失’, ‘失望’ ‘failure’, ‘ failure’, ‘bad’, ‘unfavorable’, ‘bad’, ‘mistake’, ‘ failures’, ‘ bad’, ‘loss’, ‘disappointment’ |
Again, sometimes (but not always!) the antipodes of value vectors encode the semantically opposite words.
Takeaways
It seems that when the model finds the solution, it activates positive value vectors while negative value vectors stay inactive. However, inactive value vectors can get scaled negatively (because of SiLU/GeLU) and flipped to promote the opposite direction, and vice versa for when the model hasn’t found a solution.
So we see that value vectors play some role in the model generating “solution tokens”. However, is it part of verification?
Rather, there seems to be some representation prior to these value vectors that are activating them in the first place. I think there’s still questions on (1) whether the same representation is being used for mid-layer solution tokens and final predictions, and (2) Whether value vectors play a necessary role in verification. To me, the activation of value vectors seem to reinforce the model’s decision to predict “this” or “not”, and so we might characterize them as being a component of verification, but perhaps not a requirement. TBD.
How does the model know when to activate these value vectors?
The answer is likely in the attention heads, which I plan to investigate next.
Collaborating
I would love to hear your thoughts! Please see the ARBOR page for discussions.